Serverless EMR job Part 2 - Monitor & Troubleshoot
This workshop has been deprecated and archived. The new Amazon EKS Workshop is now available at www.eksworkshop.com.
Monitoring job status
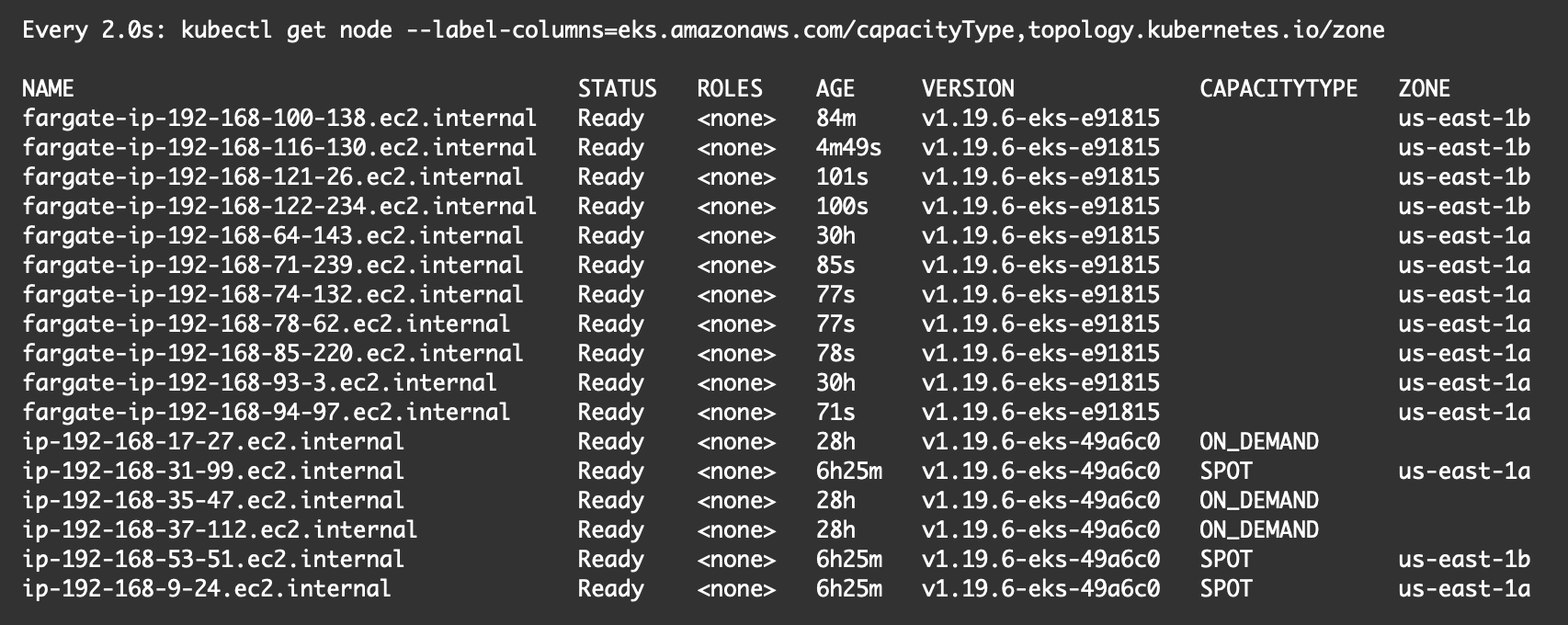
With zero manual effort, the number of Fargate instances change dynamically and distribute across mutliple availability zones. You can again open up couple of terminals and use watch command to see this change.
Watch pod status:
watch kubectl get pod -n spark
Watch node scaling activities:
watch kubectl get node \
--label-columns=eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
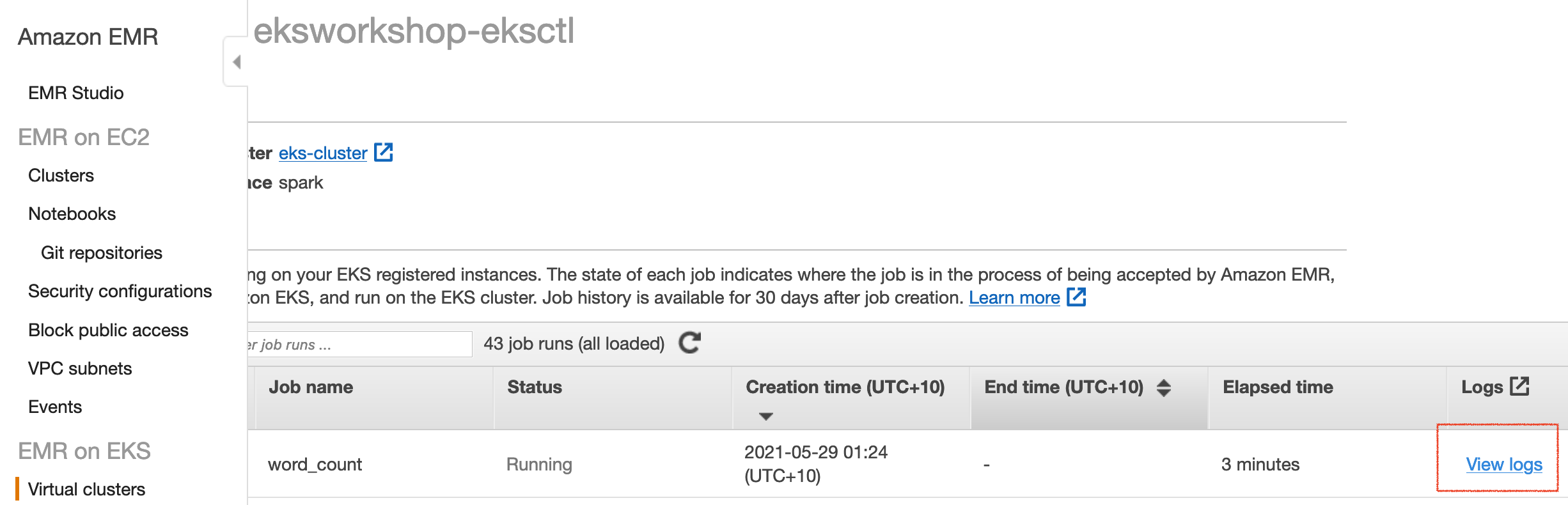
Navigate to SparkUI to view job status:
echo -e "\nNavigate to EMR virtual cluster console:\n\nhttps://console.aws.amazon.com/elasticmapreduce/home?"region=${AWS_REGION}"#virtual-cluster-jobs:"${VIRTUAL_CLUSTER_ID}"\n"
View output in S3, once it’s done (~ 10min):
aws s3 ls ${s3DemoBucket}/output/ --summarize --human-readable --recursive
Troubleshooting
Fargate has flexible configuration options to run your workloads. However, it supports up to 4 vCPU and 30 GB Memory per compute instance. It applies to each of your Spark executors or the driver. Check out the current supported configurations and limits here.
Let’s submit the same job with 5 vCPUs that is over the limit to force the failure.
aws emr-containers start-job-run \
--virtual-cluster-id $VIRTUAL_CLUSTER_ID \
--name word_count \
--execution-role-arn $EMR_ROLE_ARN \
--release-label emr-6.2.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "'$s3DemoBucket'/wordcount.py",
"entryPointArguments":["'$s3DemoBucket'/output/"],
"sparkSubmitParameters": "--conf spark.kubernetes.driver.label.type=etl --conf spark.kubernetes.executor.label.type=etl --conf spark.executor.instances=8 --conf spark.executor.memory=2G --conf spark.driver.cores=1 --conf spark.executor.cores=5"
}
}'
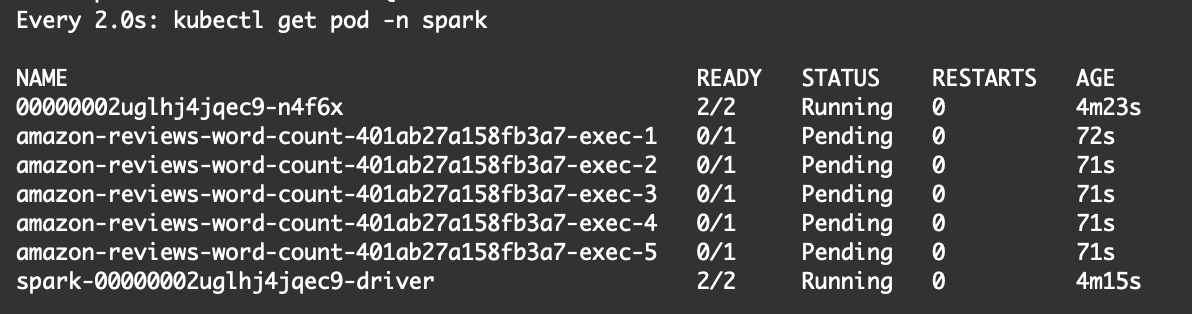
Problem - the job is stuck with pending status.
watch kubectl get pod -n spark
Wait for about 2 minutes. Press ctl+c to exit, as soon as the Spark driver is running.
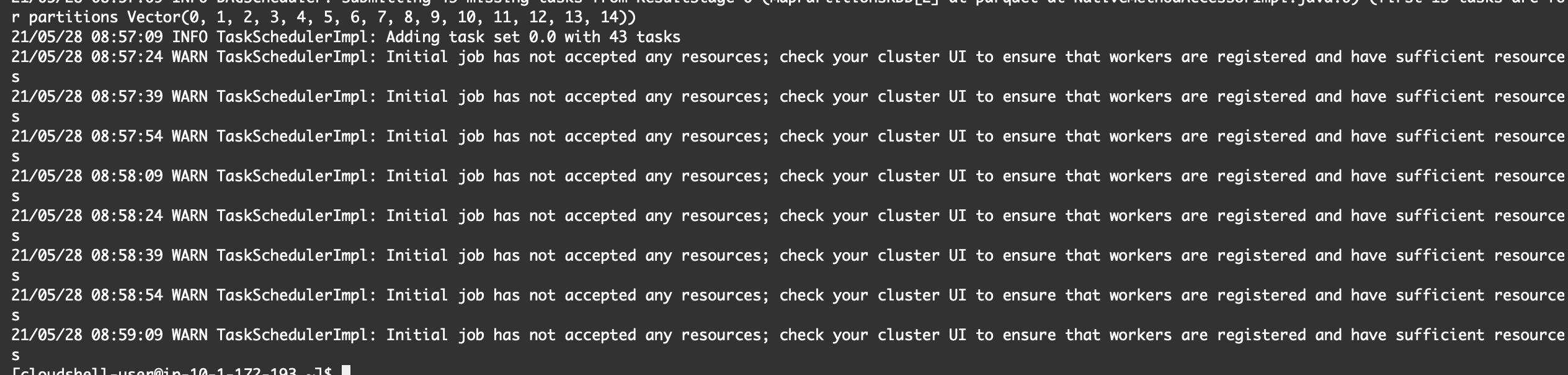
Check the driver’s log:
driver_name=$(kubectl get pod -n spark | grep "driver" | awk '{print $1}')
kubectl logs ${driver_name} -n spark -c spark-kubernetes-driver
The job is not accepted by any resources:
Investigate a hanging executor pod:
exec_name=$(kubectl get pod -n spark | grep "exec-1" | awk '{print $1}')
kubectl describe pod ${exec_name} -n spark
Congratulations! You found the root cause:

Delete the driver pod to stop the hanging job:
kubectl delete pod ${driver_name} -n spark
# check job status
kubectl get pod -n spark
